Your backlink strategy should focus only on relevant sites. Modern backlinking is no longer about the number of links. It's all about the quality of links.
Google has filed many search-related patents, and the most eye-watering takeaway is that a given webpage is ranked according to its single most important link.
Patents are curious because Google has to file them - there is no way to file a patent secretly; thus, to patent their core algorithms, Google has to make their patents legible, easy to understand, and public. If the patent is too broad, it's unenforceable.
Table of Contents
Based on the patents reviewed in this article, we can determine that modern PageRank functions in the following way.
A set of web pages is broken up into shards.
Shards are a table containing the calculated distance a given set of pages is from a given seed site.
Seed sites are hand selected by Google.
PageRank is determined according to a web page's single best link, theshortest distance from a seed site.
As a result, one could link to 30,000 random pages and pass 0 PageRank, which is different from the common interpretation of backlinking, which implies that most links pass PageRank.
The above assessments seem grand, yet, the statements all make sense in the context of what we know about web ranking.
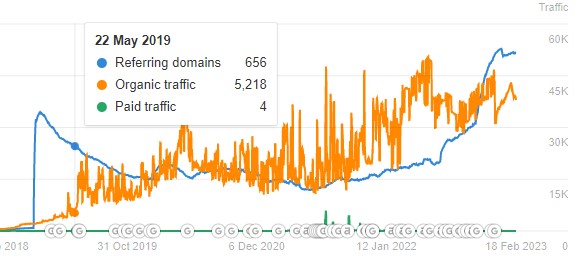
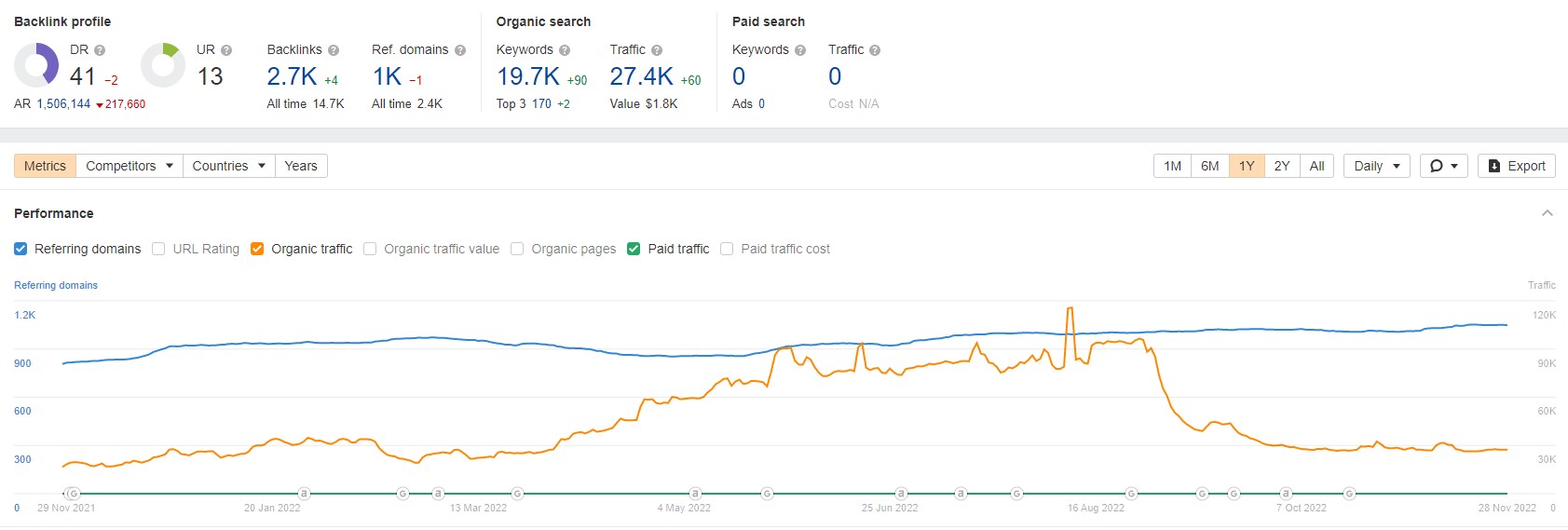
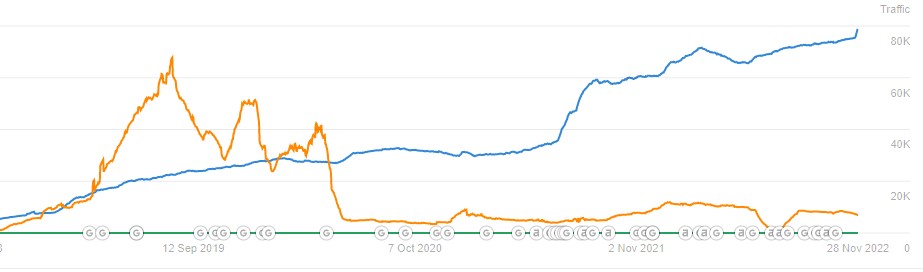
I worked in a corporate position where we tried all sorts of things to get backlinks, like guest posting. I think the bulk of our 122% increase in sessions came from algorithm updates and producing more content, not from backlinking. It's impossible to quantify what results we saw due to linking, and as someone with a background in data, I've seen some comical correlation charts posted by the SEO community.
No Obvious Link Between Backlinks And Traffic
SEOs only share positive stories about backlinking, but what about the vast majority where backlinking doesn't help and, in some circumstances, too much backlinking might even hurt? See the following charts from random websites where links didn't help.
As anecdotal evidence, Mueller has stated the following.
Don't focus on the number of links any particular tool shows -- there is no "correct" way to count links, interpretations vary wildly. Think of links as a way that people can reach your site, not as a metric of its own. The number of links any tool shows is not a ranking factor.
— John Mueller is mostly not here 🐀 (@JohnMu) July 22, 2022
The Original PageRank Formula
The original PageRank formula counted the quantity and quality of the citations to a webpage. It was simple to calculate:
PageRank = dampening factor x (total links in ÷ links out)
A patent filed in 2006 and extended as recently as 2018 shows that Google has another way to quantify backlinks. By quantifying the distance between points.
Modern backlinking is no longer about the number of links. It's all about the quality of links.
The 2006 Web-Link Distance Graph
What's interesting about the 2006 web-link graph patent is that it aligns with what Google has hinted at publicly. The patent aligns with the expiration of the original PageRank patent, also in 2006, licensed by Google but owned by Standford.
Google has stated that it files many research patents and doesn't always use them. Google has also been deeply involved in a long war against spam.
Based on what we know about the Penguin update, officially known as the “webspam algorithm update.” The following quote from the patent poses it as a solution to the spam problem.
....the simple formulation of Equation (1) for computing the PageRank is vulnerable to manipulations. Some web pages (called “spam pages”) can be designed to use various techniques to obtain artificially inflated PageRanks, for example, by forming “link farms” or creating “loops.
The Solution To The Webspam Problem
One possible variation of PageRank that would reduce the effect of these techniques is to select a few “trusted” pages (also referred to as the seed pages) and discover other pages which are likely to be good by following the links from the trusted pages....
To help visualize the new version of PageRank, ranking by distance would count the number of clicks it takes from a predetermined high authority page to any given page. Notably, this is vastly different from the original PageRank formula. For example, the Original PageRank would not use seed sites and would calculate PageRank through division.
The latest versions use predetermined seed sites and only count up to a specific distance from the initial seed site.
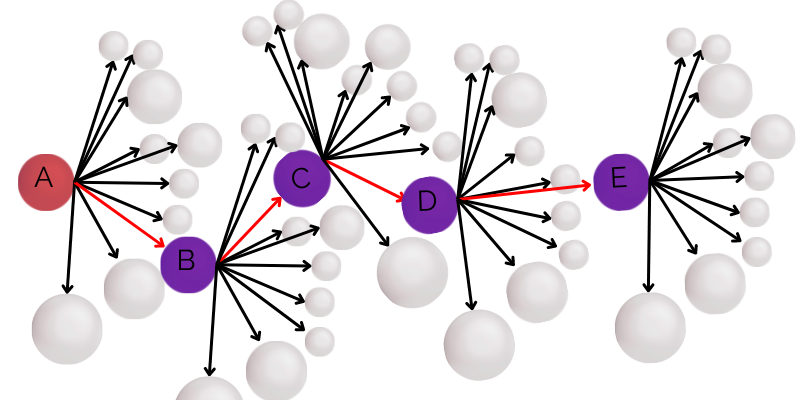
The following visual example shows how a group of pages might link in space. We can follow the red lines and see how far away page F is from page A.
The distance can be represented by the number of clicks away an authoritative page is from any random page.
Fig 2
In Fig 2, following the red lines from sphere A to sphere E, it takes three clicks from A>D>B>E.
It takes five clicks from A>C>G>F>B>E.
The web-link distance ranking method still uses division. However, the notable difference is that PageRank only passes through preselected web pages.
The flaw of the original PageRank Algorithm was that PageRank could be artificially acquired just by purchasing links. The new web-link distance method helps resolve that issue by ensuring that only links from pre-validated sites are the ones that count.
If we pretend that Site A is The New York Times and assume that The New York Times is authoritative regardless of how many backlinks it has. Then the web-link distance method passes PageRank from the New York Times to whatever The New York Times links to, and not the other way around.
As a result, a seed page like one found on New York Times no longer needs to acquire links, and the only backlinks that pass any PageRank originate from a seed page.
Using distance, the PageRank passed from A to E would increase the length at least five times(5 clicks), so the resulting link equity passed would be minimal.
How To Measure The Distance Between Webpages
I studied K-means clustering in college as part of a data science class.
K-Means Clustering is a method to measure the distance between classifications. K-means clustering measures the straight line distance between two points. These lines would occupy space in as many dimensions as there were points. We could have an 8-dimensional space or 37-dimensional space, or more. The larger the dimensional space, the larger the computing power.
Fig 1
To measure the distance, you'd sum the squares of every straight-line point and then take the square root of the sum of all those points. That process would be repeated for every classification in a given space.
The latest version of PageRank uses predetermined seed sites as the initial classifications and only counts up to a specific distance from the initial seed site.
In Google's Patent, distance ranges from n=3 to 6 clicks deep.
To visualize what the looks like, you'd take all the links on a page and follow them 3 to 6 links deep. Each additional click could lead to a page with more links on the page; this problem is exponential.
Assuming that Google uses 10 seed sites each with 10 links, linking to 10 pages with 10 links each. Six iterations are 10 to the power of 6, or 1 million edges.
Assuming that Google uses 100 seed sites, each linking to 10 pages with 10 more links each. Six iterations are 100 to the power of 6, or 1 trillion edges.
n=4 Link Visualization
How The Google Patent Defines Link Distance
Google adds an extra layer to the complexity of the measurement; they add weights to links based on attributes.
The length of a link can be a function of any set of properties of the link and the source of the link. These properties can include, but are not limited to, the link's position, the link's font, and the source page's out-degree.
Source page's out-degree: Fancy way of saying the total number of pages that a given page links too.
The Problem With Ranking By Link Distance
An issue arises when there are too many pages. With 4 billion web pages, computing a system with an extensive dataset multiplies the computing intensity. And a good ranking algorithm would want to represent many niches and languages with a large seed set.
How others have approached this same problem is to break the seed pages into groups by topics. Majestic’s Topical TrustFlow, and similar research demonstrated that a seed set organized by niche topics is easier to implement.
Google does not use topical clusters.
Clustering With The Reduced Link Graph
Google solved the massive computation problem by creating a "reduced link graph," which counts only the shortest link path instead of all link paths.
We are interested in determining a “shortest” path from seed 102 to page 118 among all of these possible paths, wherein the shortest path will be subsequently used to determine a ranking score for page 118.
Google does the initial calculation but only uses the single best link to determine PageRank.
Examine Fig 3. Seed pages A, B, and C link to the other web pages in several ways.
Fig 3
In Fig 3, to determine the distance of G, you could use either the distance from A > D > E > G.
Or the distance from B > E > G.
The shortest distance of the two is used for the ranking.
By counting only the shortest path, a site could link 30,000 times to a given site and pass no PageRank. In previous models, 30,000 links might pass PageRank.
Note that similar to assigning the kth largest value of Ri(p) as the final PageRank R(p), we have set the final “shortest distance” for page p as the kth shortest distance among the set of shortest distances...
Thus, a page rank for a given webpage is determined by one link string. That doesn't mean we shouldn't go out and get more links. It just means that the outdated backlink strategies may not be nearly as effective as they used to be.
Modern Linking Is About Quality, Not Quantity
Modern backlink strategies should be to reduce the distance between your site and a given site of hefty importance. Think of it this way. Being a friend of a friend of a friend who was interviewed by the New York Times is cool, but being interviewed by the New York Times is better. Our goal as marketers should be to get interviewed by the New York Times.
Links still help in other ways, like with anchor text.
Counting a page's best link is a benefit in some ways. We no longer have to stress about getting links on random websites.
PageRank Weighting Decreases Over Time
The fact is that as Google adds more and more ranking factors, the weight of any single ranking factor must diminish because the sum of all ranking factors must equal 100%. PageRank in 1998, combined with a simple keyword-based content score, might have been split 50/50; PageRank might have had outsized importance in 1998.
Today's system is much more complex. That conceptually suggests that if Google adds 200 additional ranking factors, each has less and less impact on the overall ranking results.
Also, PageRank does not make sense for relevance in some circumstances, like a map or local business query; PageRank is entirely irrelevant in those circumstances. PageRank was never perfect, and as time progresses, it makes sense that PageRanks impact should continue to diminish.
I'm not saying links don't matter, just that they don't matter nearly as much as they used to.
A presentation in 2016 by Paul Haar, a Senior Search Engineer at Google, provided insight into where PageRank might fit into the ranking algorithm.
SMX 2016 Conference
Topical Backlinking: A 2009 Google Patent Expands On The First
Some SEOs theorize that Google applies the reduced web-link graph through topical seed sets. However, Google has never stated as much. Another patent filed on Aug. 7, 2009, built upon the idea of the reduced link graph.
Google noted that it built upon the previous patent, "U.S. application... entitled Method and apparatus for producing a ranking for pages using distances in a web-link graph...”
The following is from the second patent filed in 2009, which builds upon the patent filed in 2006.
A directed graph representing web resources and links are divided into shards, each shard comprising a portion of the graph representing multiple web resources. Each of the shards is assigned to a server, and a distance table is calculated in parallel for each of the web resources in each shard using a nearest seed computation in the server to which the shard was assigned.
The 2009 patent perfects what was discussed in the 2006 patent. They decided to use a reduced link graph and apply it with servers worldwide instead of trying to do it with one central set of seeds.
The method is scalable, and the system computes the shard distances with each seed server and combines the resulting tables. Also noted in the patent, this solution addresses the machine failures which resulted from calculating "trillions of edges."
A presentation by Paul Haar, a senior search engineer at Google, provided insight that the shards used in queries are not the same shards used for PageRank.
SMX 2016 Conference
Visualizing The Single Shortest Distance Ranking By Link Distance And Shards
Google identifies the important seed pages manually.
In some implementations, seeds are identified using a partially or fully manual process and provided to the system as a list of page identifiers. As already mentioned, in the system the data and the processing are distributed across many servers, in some implementations, across more than one thousand servers. Each server processes a shard of the input and output data corresponding to its nodes.
In the following visual, I identified which sites are important based on subjective qualitative factors.
Those core seed pages are identified as A, B, and C. We've selected them as the seeds of our clustering algorithm because they are very trustworthy and authoritative.
We can calculate the distance between each webpage and the three seed pages by the shards assigned to the seed pages and rank the subset of pages based on the shortest distance. This allows many PageRank calculations to run simultaneously and in all languages and topics.
After the computations are done across multiple servers, the ranking tables are combined. So a given page could end up with numerous shortest distances in various tables. A page could be linked to by both the New York Times and Google. The combined model would use the absolute shortest distance.
In the following visual, "I" is linked to multiple seed sites; each calculation produced the shortest distance for the site "I."
Page B links to page I
Page A links to page I
Recall that length was defined as a function of several factors such as font size and page location, so one link might be in the <footer>, while the other might be on the <body>. Indeed a link in the footer should not carry the same weight as a link in the body of a page. It's hard to tell visually, but the Link from page "B" to page "I" is longer than the link from page "A" to "I."
Fig 4
Note how in Fig 4, page "I" has the shortest distance from shard A or shard B. The final algorithm would pick the absolute shortest distance from all the tables it was provided.
So the shortest distance to page "I" is through seed page "A," the other distance is not used in the final PageRank scoring.
The algorithm does this for every single page on the web.
Conclusions From Calculating Rank By Link Distance
In any scenario, it is evident from several Google patents that random links will not help you. It would help if you focused on quality links over the number of links.
Some added benefits of ranking by link distance
Allows sites linked indirectly from one government site to receive higher link equity than a site with a million links and an exponentially higher domain rank.
The number of links does not matter at all.
Smaller sites with one good backlink from a good site might add more link equity than a large site with millions of high DA backlinks.
If you had told me a couple of years ago that I could type "a cyberpunk hedgehog making a latte" and get a photorealistic 4K video back in seconds, I would have laughed. But here we are in 2026, and AI video generation isn't just a novelty anymore, it's a massive part of my daily workflow.
This guide leverages my experience to break down how to write, structure, and publish a document that earns trust rather than just demanding attention.
Depending on who you ask, there are anywhere from five to twenty "essential" rules out there. But in my experience, there are really only a dozen “laws” of visual design that matter across every medium. Here’s a guide I’ve created with the elements I find to be the most important, no matter your platform.
I love WordPress for its customizations. Styling code snippets enhances user perceptions. Copy and paste the code below to style your WordPress code blocks.
If you had told me a couple of years ago that I could type "a cyberpunk hedgehog making a latte" and get a photorealistic 4K video back in seconds, I would have laughed. But here we are in 2026, and AI video generation isn't just a novelty anymore, it's a massive part of my daily workflow.
This guide leverages my experience to break down how to write, structure, and publish a document that earns trust rather than just demanding attention.
Depending on who you ask, there are anywhere from five to twenty "essential" rules out there. But in my experience, there are really only a dozen “laws” of visual design that matter across every medium. Here’s a guide I’ve created with the elements I find to be the most important, no matter your platform.
I love WordPress for its customizations. Styling code snippets enhances user perceptions. Copy and paste the code below to style your WordPress code blocks.