Search engines algorithmically weigh variables, such as the presence of words in the title, then produce a score based on those calculations.
Relevance scoring is a quantitative way to measure the relevance of a given piece of content.
I rarely see factual information on relevance scoring. Mostly because each system is unique and proprietary. As a result, some outdated ideas on relevance scoring persist today. Though, relevance scoring is field of study, meaning the basics can be taught.
For example, some SEOs overemphasize the importance of putting keywords in a URL to help a webpage rank better.
I have seen website administrators change all their URLs only to experience a significant drop in organic traffic and wonder why this well-known piece of advice did not help.
John Mueller from Google has stated that keywords in a URL have minimal impact on relevance.
"The SEO effect of keywords in the URL is minimal once the content is indexed. Make URLs that work for your users, not for SEO. Also, changing URLs on an existing site is a site-migration & it will take time/fluctuations to be reprocessed, so I'd avoid that unless it's critical.— John Mueller is mostly not here 🐀 (@JohnMu) August 19, 2020"
Ten years ago, however, words in the URL were a significant part of the relevance scoring system, but today they are a minor part, which explains why SEOs still tout the importance of keywords in the URLs.
What changed? URLs on mobile are truncated, and users rarely see them anymore. And keywords in a URL don't necessarily help sort content accurately.
Table of Contents
Relevance Score Definition
According to Wikipedia, "relevance denotes how well a retrieved document or set of documents meets the information need of the user." It makes sense that putting words in a URL does not necessarily improve a user's needs-met rating.
Do Links Signify Relevance?
In the same light, it makes sense that links don't signify authority or relevance all the time; for example, when you're looking for expert advice, should the number of links matter?
Do you ask your Doctor how many links he has to his site before taking his opinion seriously? Probably no.
The idea of relevance is the whole premise of why search engines exist. Relevance scoring is what an SEO attempts to manipulate, regardless of the search system.
I put this post together to try and break down relevance scoring into simpler terms. Hopefully, by reading this article, you will come away with a deeper understanding of how search works.
What Is Relevance Scoring?
Information science, or informetrics, is the parent field of bibliometrics and webometrics. The idea of relevance applies to information science as a whole, and it helps users find library books or helps users find information on the web.
Relevance scoring has gone through many iterations. The earliest forms of relevance originated in the 17th century in attempts to sort scientific journals. According to Wikipedia, the study of relevance as a formal subject comes from the 20th century, under bibliometrics - the field used to sort library books.
Imagine the original informetric systems used in libraries, with library cards and old 1980's Tandy computers that pulled up books based on a numbering system, where they ranked the books alphabetically and by genre. These systems were some of the first search engines.
Old Informetric System A Phone Book
In that same light. Recall the old phone books; they were a business directory dropped off at people's houses for free.
Businesses would pay a fee to be included in the "Yellow Pages." The phone book was one of the primary ways businesses got customers for decades. The Yellow Pages would rank businesses by business category and alphabetically.
As a result, companies started popping up with multiple "A's" in their business names, like "AAA Plumbing" or "AAA Hardware."
The use of repetition to manipulate a search system sounds oddly familiar.
Systems that rank results alphabetically may not serve the best search results for every query. The original web-based search engines had similar, easy-to-manipulate flaws as phone books.
Some of those web-based search systems are still in use today.
2022: My college's ancient web-based relevance scoring system
Government sites and colleges still use some of the old relevance scoring systems.
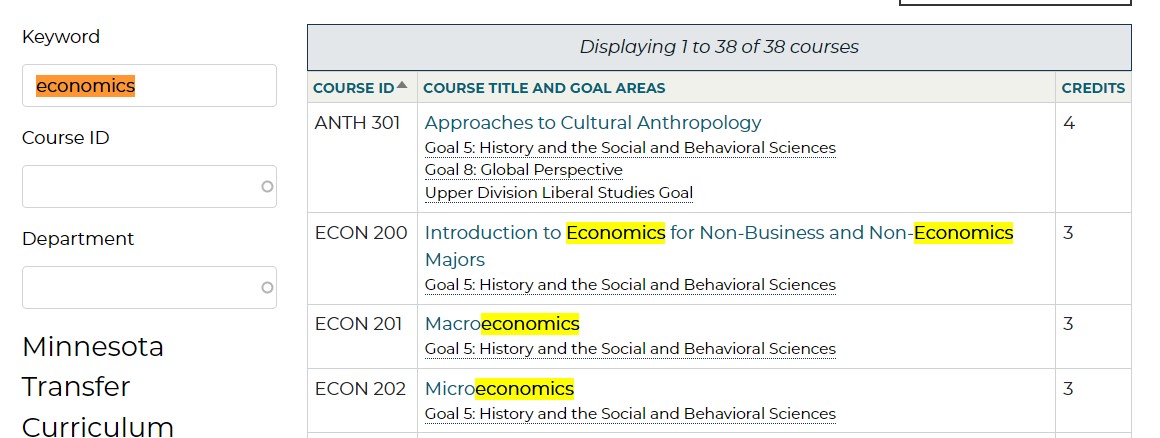
The search function on an old website might return the results alphabetically based on the book's title. Or, in the case of my college, alphabetically based on the title and used data from the entire course description.
I typed the search term "economics" in my college's course directory, and it returned courses that included the term "economics" anywhere in their descriptions, in alphabetical order.
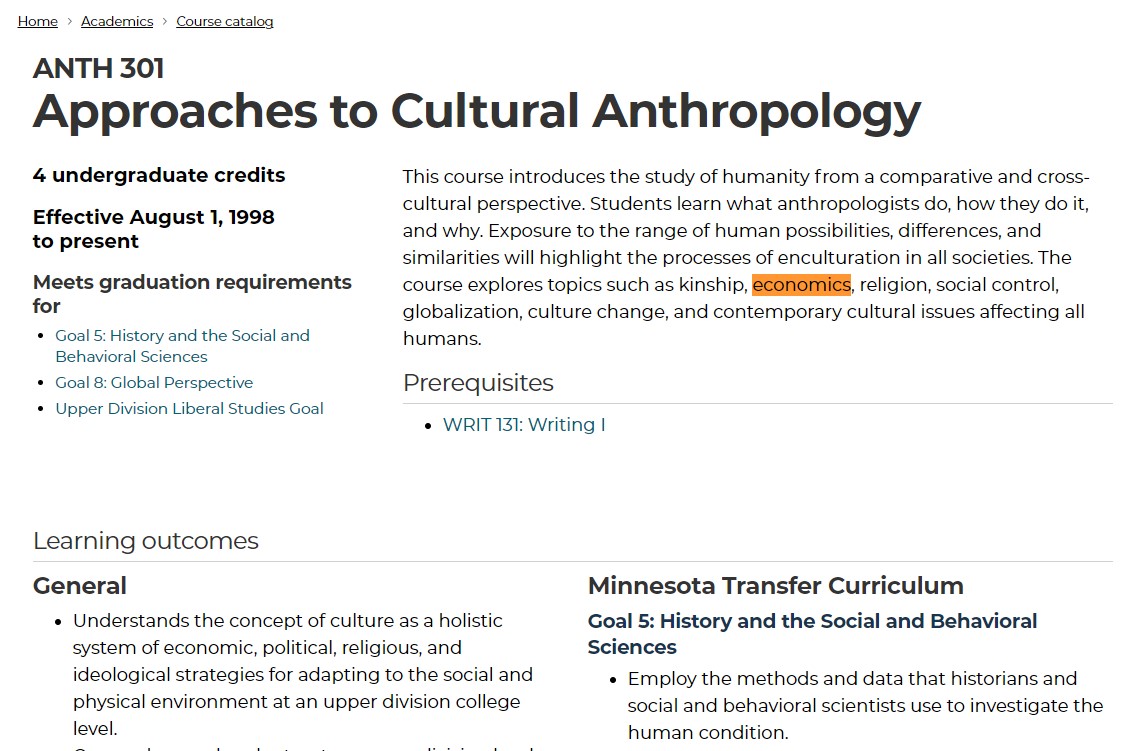
Now for a college with 38 results, it is not a big deal if the course at the top of the search page is not an economics course. ANTH 301 matched the term "economics" because it contained the term in its course description.
If you searched for "books about SEO," you would find more than 103 million results on Google; the last thing you'd want is to return results alphabetically.
Let's see if we can come up with a way to score the content on my college's search directory to help improve the relevance of the search results.
Relevance scoring
One way to help my school's search engine return better results would be to count and weight additional variables that determine relevance. For example, you could look for the phrase in other places and count the number of times the term is repeated.
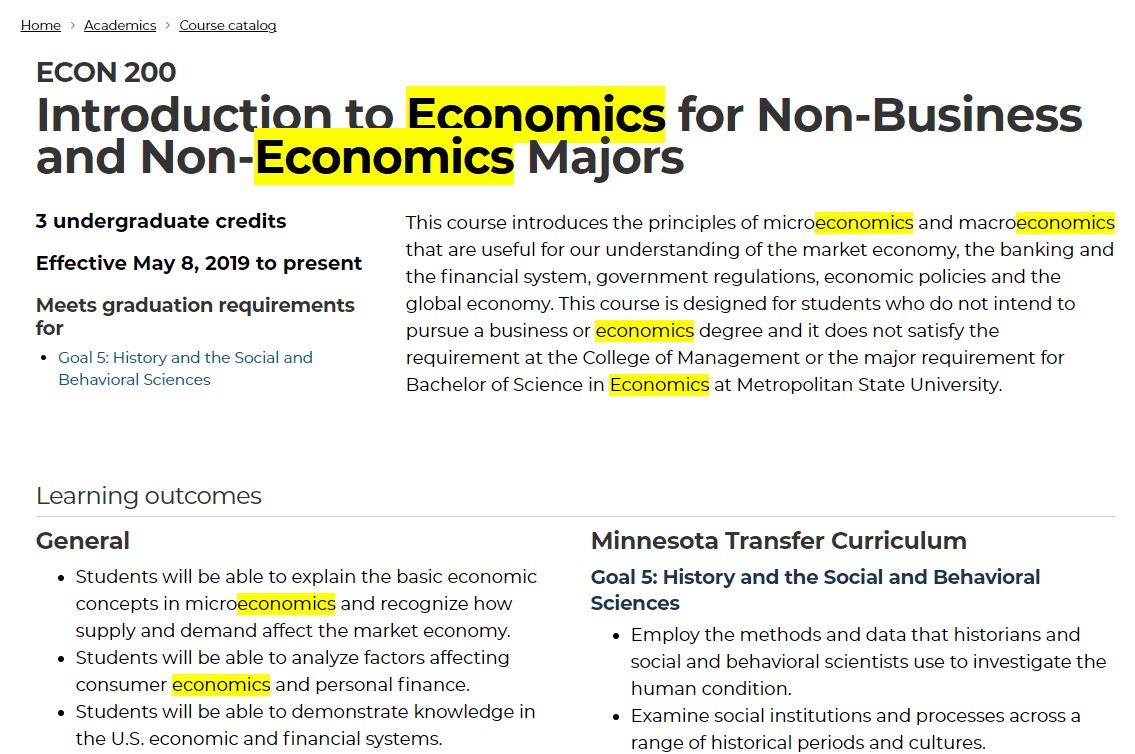
I counted the term "economics" 1 time on ANTH 301's webpage. I counted the term "economics" 10 times on ECON 200's webpage.
I found 11 repetitions of "economics" on ECON 201's webpage. And 13 repetitions of "Economics" on the ECON 202 webpage.
Based on the above assessment. My former college's search engine only looked for the inclusion of the keyword at least once; it did not count the repetitions or weigh the results based on other factors.
We could add variables such as repetition, meta description, meta title, and page title. Or any variable that we think is relevant.
Each variable could be assigned a number, which can be weighted if we choose. For example, a page with 8 repetitions could be represented by the number 8 or the number 4.12534536 on a logarithmic scale. The choice is ours. In the end, the sum of all the ranking factors must equal 100%.
Working with my former college's course index. A simple relevance scoring system could look something like this.
Search Term
Page Location
# of RepetitionsIncluding Footers
Page Title Repetitions
Summary Section Repetitions
Outcome Section Repetitions
Author Score
SUM of ScoresExcluding Footers
"Economics"
ANTH 301
1
0
1
0
0
1
"Economics"
ECON 200
10
2
4
2
5
13
"Economics"
ECON 201
11
1
0
2
5
8
"Economics"
ECON 202
13
1
0
1
5
7
If it finds the search term in the title, it returns a "1"; if the term is in the title twice, it returns a "2." To keep it simple, we are counting repetitions and weighing results based on where those results are presented.
With R studio, for example, we could create something more complex. We could double the weight of the presence of the keyword in the title or stop counting repetitions after a certain number.
Weighing unnecessary repetitions
In the example content scoring system above, I have chosen not to count the repetition of the words in the footer section because they don't help us determine if the content is relevant.
Weighing expertise
It's hard to quantify an author's expertise and relevance to a given query without the necessary credentials. Why? Because without credentials, how do I know the content is expertly written? Should I take the author's word for it? Over a factor of near-infinite search terms, the problem is exacerbated.
Based on the authors' degrees below, who is objectively authoritative on economics? The Master of Economics or the Master of Anthropology?
Thus, we should weigh articles written by qualified experts higher than those written by unqualified experts. And that makes perfect sense; plenty of people give non-expert opinions; think of all the high-profile personalities. It doesn't matter how many articles a given personality has read. They are not a qualified expert.
Search Term
Page Location
Author Score
"Economics"
ANTH 301
0
"Economics"
ECON 200
5
"Economics"
ECON 201
5
"Economics"
ECON 202
5
I added the field "author score"; this is either 0 or 5, based solely on the professor's education. If one or more professors teaching a class has an advanced degree in economics, the class receives a score of 5, while a class taught by a non-economics professor gets a score of 0.
The final content scores
As a result of our new and improved content scoring system, when users look for the term "Economics," they are shown results based on the content's relevance score, which we calculate below.
ANTH 301 Content Score = [1+0+0] = 1
ECON 200 Content Score = [2+4+2] = 13
ECON 201 Content Score = [1+0+2] = 8
ECON 202 Content Score = [1+0+1] = 7
When a user is shown the results, the are now ordered by their content score: ECON 200, ECON 201, ECON 202, ANTH 301.
We moved ANTH 301 to the bottom of results.
ANTH 301 moved to the bottom of the search results
We've improved my old college directory's search results. You're welcome.
But now it's time to move on to bigger things. The web is vast, and sorting four college courses might not cut it.
Also, with our current system, one could easily manipulate the search rankings by repeating the search term all over a page, which is precisely how the original search engines were manipulated.
Also, a system ranked alphabetically might be preferred in some contexts, like searching for classes. So maybe we did all this work and made the results worse?
Now that we've explored relevance scoring. We can try to combine this concept with the idea of backlinking.
How do backlinks work with relevance scores?
Modern informetric systems are much more complex than the ones used in school systems, if only for the size and complexity involved in contemporary content organization.
So you'd take the content rankings from above and overlay backlinks. You’d then have two scores, one for content within the index and one for the number of citations a piece of content receives; in theory, content with more citations is more authoritative. Content with a higher relevance score is more relevant.
Combined, these two scores would produce exciting results because you could technically have a higher-quality page, but another site could have a better link profile. They could both populate in the top spots. However, you'd also limit the number of results appearing for a given query to a reasonable amount.
Relevance scoring is an essential part of any search index. There are obvious limits to how it can be approached. To score content, the algorithm has to be able to read the content; how it weighs the content is entirely up to the engineers.
Machines are not yet smart enough to make subjective interpretations, so the machine has to be able to interpret the content easily, and it has to do so through text that exists in the same online matrix, in an easily digestible format. Meaning offsite and onsite factors have to be known - they are things on a webpage or in the code somewhere.
Things that we humans interpret as subjective, like expertise or quality or trust, have to be measured objectively; otherwise, the algorithm cannot understand them.
If you had told me a couple of years ago that I could type "a cyberpunk hedgehog making a latte" and get a photorealistic 4K video back in seconds, I would have laughed. But here we are in 2026, and AI video generation isn't just a novelty anymore, it's a massive part of my daily workflow.
This guide leverages my experience to break down how to write, structure, and publish a document that earns trust rather than just demanding attention.
Depending on who you ask, there are anywhere from five to twenty "essential" rules out there. But in my experience, there are really only a dozen “laws” of visual design that matter across every medium. Here’s a guide I’ve created with the elements I find to be the most important, no matter your platform.
I love WordPress for its customizations. Styling code snippets enhances user perceptions. Copy and paste the code below to style your WordPress code blocks.
If you had told me a couple of years ago that I could type "a cyberpunk hedgehog making a latte" and get a photorealistic 4K video back in seconds, I would have laughed. But here we are in 2026, and AI video generation isn't just a novelty anymore, it's a massive part of my daily workflow.
This guide leverages my experience to break down how to write, structure, and publish a document that earns trust rather than just demanding attention.
Depending on who you ask, there are anywhere from five to twenty "essential" rules out there. But in my experience, there are really only a dozen “laws” of visual design that matter across every medium. Here’s a guide I’ve created with the elements I find to be the most important, no matter your platform.
I love WordPress for its customizations. Styling code snippets enhances user perceptions. Copy and paste the code below to style your WordPress code blocks.